Summary
Recall that feedforward networks are a divide-and-conquer approach: many simple nonlinearities combine to form a highly expressive model. We can think of a neural network as a map from an input space to an output space:
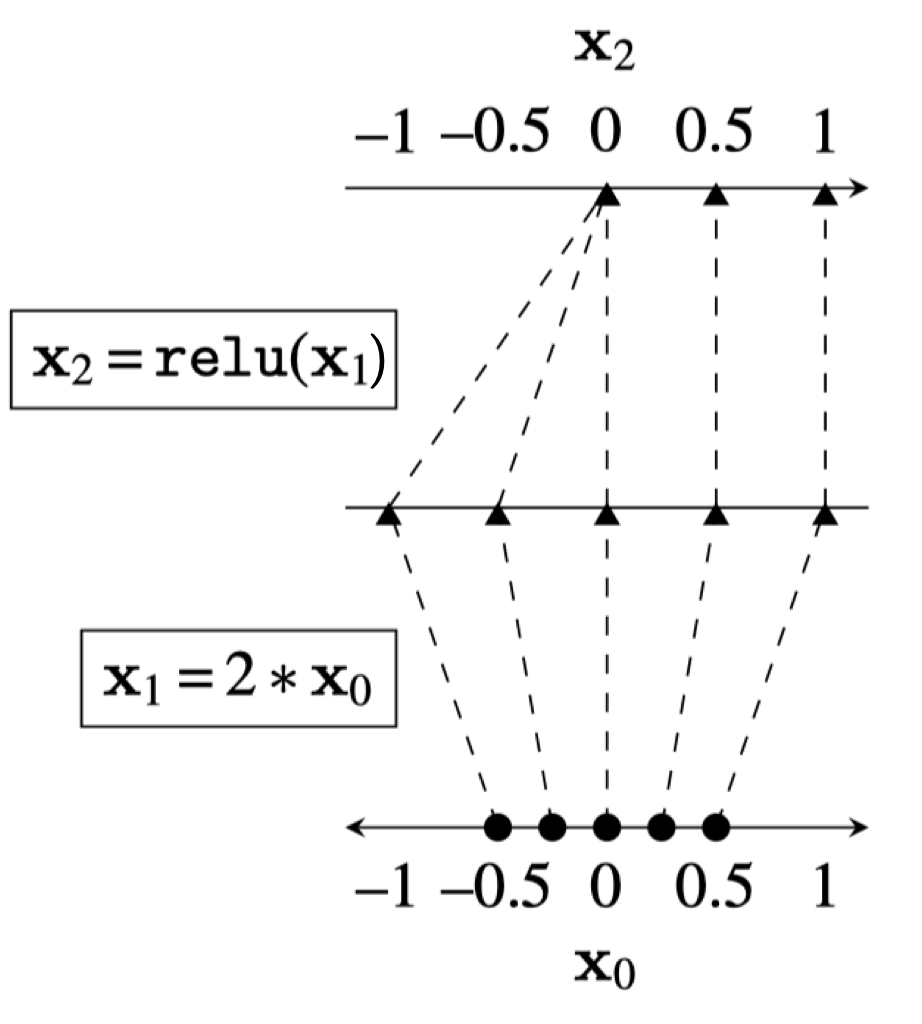 What does training a neural network classifier really look like? We want to turn a complex space into a simpler one where classes are easier to separate. Deep neural networks transform data point by point, layer by layer. Each layer is a different representation of the data, and the map from data to latent embeddings is the essence of feature transformation and representation learning.
What does training a neural network classifier really look like? We want to turn a complex space into a simpler one where classes are easier to separate. Deep neural networks transform data point by point, layer by layer. Each layer is a different representation of the data, and the map from data to latent embeddings is the essence of feature transformation and representation learning.
Good representations are compact (minimal), explanatory (roughly sufficient), disentangled (independent factors), interpretable (understandable by humans), and useful for later problem solving.
Self-Supervised Learning
In supervised learning, the training target comes from human labels. In self-supervised learning, the model creates its own target from the input data itself.
One common trick is to hide part of the input and ask the model to predict the missing part. Another is to make two views of the same example and ask the model to match them. In both cases, the target is generated from the data, not from a human label.
This is harder than ordinary supervised learning, but it forces the model to learn structure in the data instead of memorizing labels.
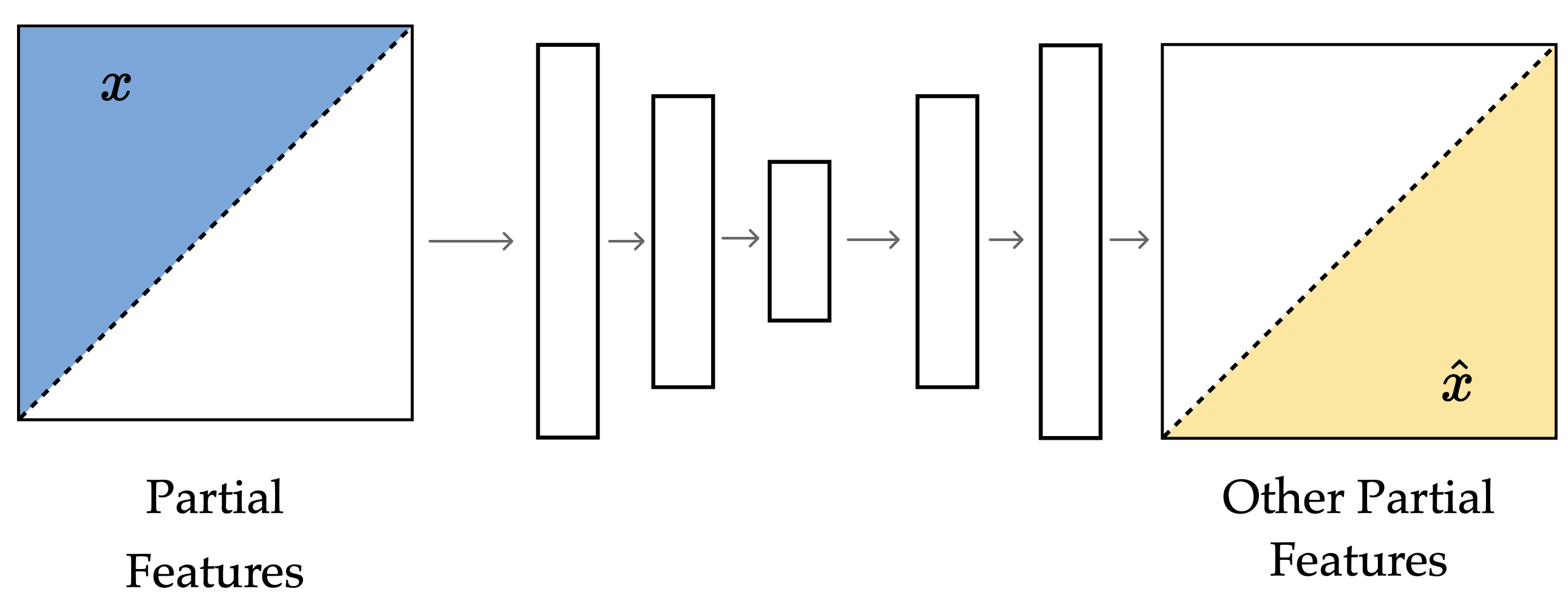
Masked Autoencoder
The idea is to hide parts of an image and ask the model to fill in the rest. The model has to use the visible patches to infer the missing ones, which pushes it to learn relationships that describe the image rather than just copy pixels.
Example
We can mask channels, like trying to predict color from grayscale.
Autoencoders
Autoencoders aim to produce compact, explainable representations. The other properties can emerge too, but they are not the main objective.
An autoencoder takes an input , compresses it through an encoder into a smaller bottleneck representation, and then uses a decoder to reconstruct as . It is trained by minimizing reconstruction error, so the bottleneck learns a compact summary that preserves the information needed to recover the original input.
There is a tension between the encoder and decoder. The encoder wants to compress the input as much as possible, while the decoder needs enough information in the bottleneck to reconstruct the input well.
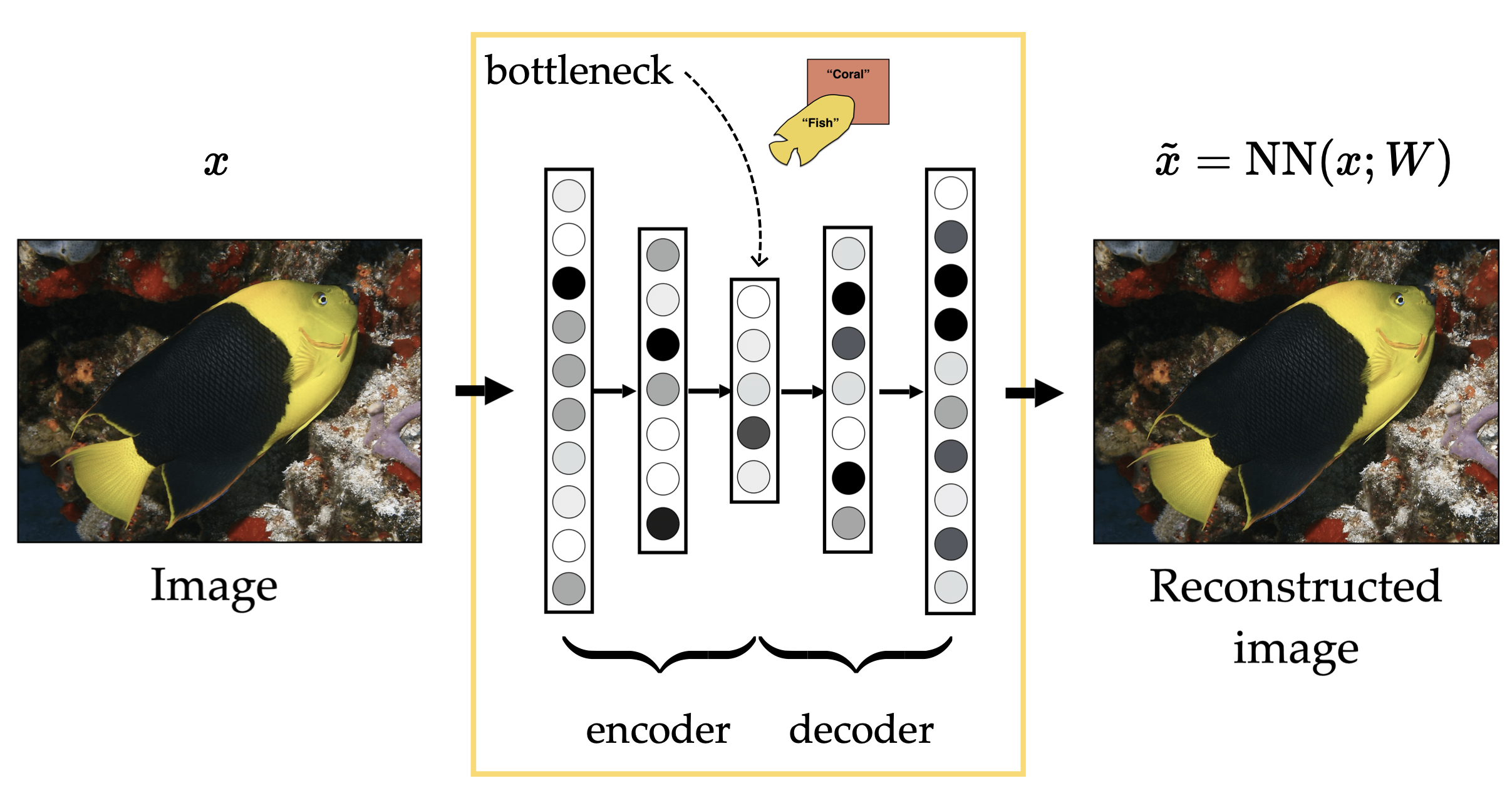 In short, the input space is high-dimensional and irregular, while the representation space is low-dimensional and much more regular.
In short, the input space is high-dimensional and irregular, while the representation space is low-dimensional and much more regular.
Often, the task we test on is not the same as the task we trained on.
Example
We might train on genre recognition and then test genre preference.
This is final-layer adaptation. The network is usually split into two parts:
- : the shared representation, or feature extractor
- : the final layer trained for the original task
After pretraining, we freeze and replace with a new final layer for the new task.
- maps the learned features to the original labels
- maps the same features to the new labels
- stays fixed because it already learned useful structure from the first task
So the workflow is:
- Pretrain and on a source task with lots of data
- Freeze
- Train on the new task with much less data
The point is that the representation learned on one task can still be useful for another task, even when the labels change.

This can be split into three phases:
- Pretraining, for example genre recognition, which uses lots of data
- Adapting, for example preference prediction, which only needs enough data to fit the new final layer
- Testing, which just applies the adapted model to new inputs
Word Embeddings
LLMs are often trained in a self-supervised way: the model sees text and learns to predict a missing or next token from the surrounding context. The text itself provides the training signal, so no human labels are needed.
The goal is to learn an embedding space where related words and contexts end up near each other. In that space, dot-product similarity becomes meaningful, so retrieval is more like a soft match than an exact dictionary lookup.
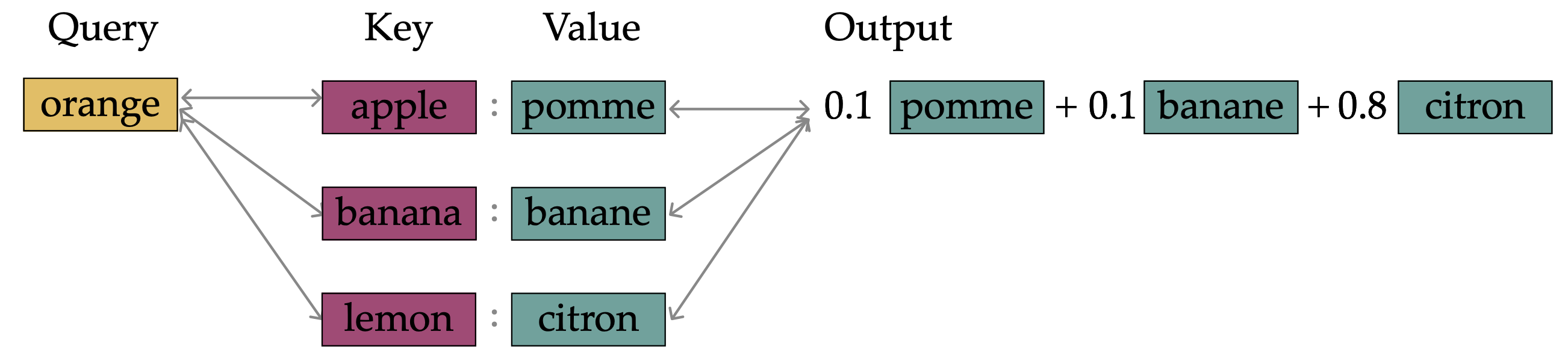
Very roughly, attention uses the same idea at inference time. Query and key vectors determine how much each value should matter, so the model can choose the most relevant information from context instead of making a hard, single choice.