Summary
Hash tables implement dictionaries in expected time per operation by using a random hash function to map keys into buckets. Deterministic hash functions always have adversarial worst cases, so we randomize. A universal hash family guarantees low collision probability for any pair of keys, which (combined with chaining) gives expected time. We construct such a family using modular arithmetic with random coefficients over a prime modulus.
We will discuss implementing dictionaries with hashing. This will combine Randomized Algorithms with Amortized Analysis.
Dictionaries/Maps
Dictionaries involve associations between pairs of objects.
We want to support the following interfaces:
Insert(k,v)- add key-value pair at indexDelete(k)- if there is an item , set to NULLSearch(k)- return entry at index We define the following notation:- universe of all possible keys
- # of objects in dictionary
- “size” of dictionary - what does this mean? We will explore We will assume that the size of is way bigger than , and for convenience, everything in is nonnegative integer.
Direct addressing
Allocate an array of size . Each key maps directly to index . All 3 operations are , but the space is , which is huge.
Doubly Linked List
Insert(k,v)- add node with at headDelete(k)- traverse list to find s.t. and update pointersSearch(k)- traverse list to find Constant insertion but linear deletion and search. Space is better: .
Balanced Search Trees
Create a balanced binary search tree. All operations take , a decent compromise.
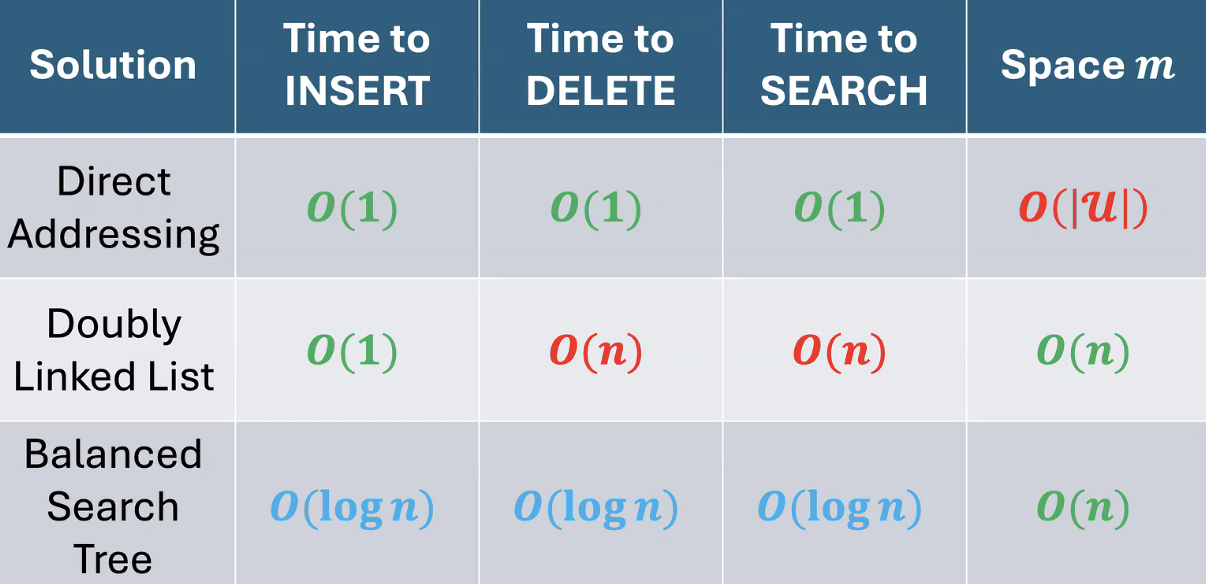
| Approach | Insert | Search/Delete | Space |
|---|---|---|---|
| Direct addressing | |||
| Doubly linked list | |||
| Balanced BST | |||
| Hashing (goal) | exp. | exp. |
Hashing
We like that array lookups only take constant time. What if we kept that but used a hash function to reduce the universe size?

Each operation involves . But how do we handle collisions, given we have keys with the same hash value? Additionally, how do we choose a “good” hash function? What even makes it “good”?
Collision Resolution
Chaining
We combine the array approach with the doubly linked list approach.
Insert(k,v)- store at head of doubly linked list at indexDelete(k)- go to and delete node with keySearch(k)- go to and search inside
Example
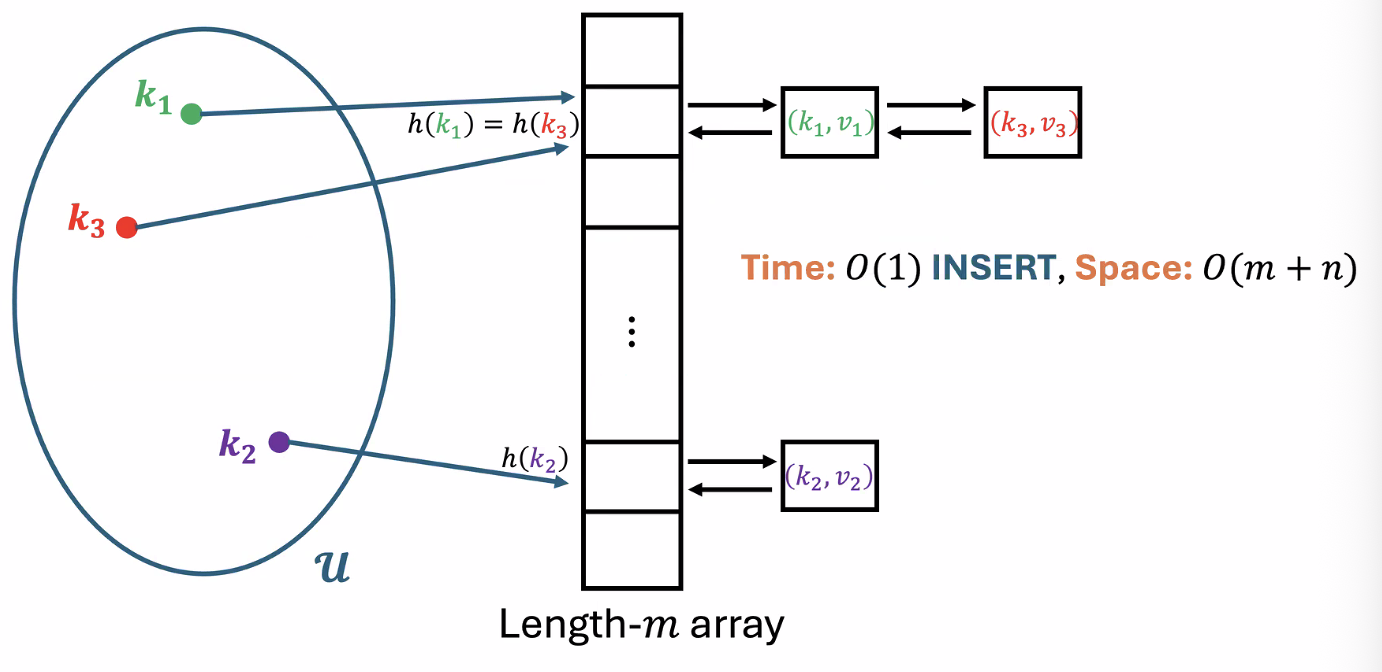
But what is the complexity of Delete and Search?
is the load factor. This is when . However, an adversary can realize what the hash function is and add elements that hash to the same place. Then, the worst-case runtime of Search and Delete is .
Corollary
Any deterministically chosen hash function will fail in the worst case
The solution to this problem is randomness. We assume the adversary can see our function, but he cannot see the random bits our algorithm uses. We aim to prove the following. For every :
Why not strengthen the quantifiers to something like
Because this is impossible. is much larger than , so by the pigeonhole principle there must exist keys that collide under any fixed . No single hash function can spread every possible set of keys evenly. The original guarantee is still strong: the adversary picks the keys before seeing our random choice of , so for any fixed input the hash function works well with high probability.
We will prove an easier goal:
Random Hash Function
Let’s try picking a uniformly random function . In other words, for every , independently sample .
We claim that for all buckets and all sequences of keys, if we let be the number of keys landing in bucket , then
To prove, let . Using the same indicator variable technique from Quick Sort: by linearity of expectation.
The practical problem with this is that we need an efficient way to store and query the mapping . This is as hard as the original problem!
Definition
A family of hash functions is uniform if
Is this enough to guarantee few collisions and a fast running time? No. Consider the family of constant functions where for all . This family is uniform (a random from sends any key to each bucket with probability ), but once a single is chosen, every key lands in bucket . Uniformity only constrains individual keys, not the relationship between different keys.
Definition
Fix an arbitrary sequence of keys . Let
SearchandDeleterun in time.
We claim that for a uniformly random function, we have
To prove, let . Then
&= sum_(j' != j) EE_h [Y_(j,j')] \
&= sum_(j' != j) PP[h(k_(j')) = h(k_j)] \
&= sum_(j' != j) 1/m \
&= (n-1)/m$$
> [!info] Definition
>
>A hash family $cal(H) subset.eq {"all" h: cal(U) -> {0,...,m-1}}$ is **universal** if
>$$
>PP_(h ~ cal(H)) [h(k) = h(k')] <= 1/m quad forall k != k' in cal(U)
>$$
>
>This is the key upgrade over uniformity: it constrains the joint behavior of *pairs* of keys (related to [[Conditional Probability & Independence#independence|pairwise independence]]).
> [!tip] Corollary
>
>Let $cal(H)$ be universal and assume $H ~ cal(H)$ require $O(1)$ time to evaluate on any key $k in cal(U)$. Then for any key, the expected runtime of `Search` and `Delete` is $O(1 + alpha)$.
The space complexity of this method is $O(m + n)$. Assuming we have a universal hash family, we can guarantee:
![[attachments/Pasted image 20260224120547.png]]
Our new goal is to make a universal hash family that evaluating $h(k)$ takes constant time and we can represent all $h$ in $O(n+m)$ space. In practice, we pick a "complicated enough" deterministic function.
### Universal Hash Families
Since $cal(U)$ is nonnegative, how about we use *modular arithmetic*? The simplest way would be to make $h(k) = k mod m$. This is deterministic, so it doesn't work. Let's try $h_s (k) = k + s mod m$ for a uniformly random shift $0 <= s <= m-1$. This still is bad as it has the same collision process since $s$ just permutes the buckets. (i.e. if two keys collide under some function, they collide under all functions)
What if we try $h_t (k) = k dot t mod m$ for a uniformly random $0 <= t <= m-1$? Notice that for many $k$, only a fraction of the buckets are used. This seems pretty wasteful. But this only happens when the multiplicative shift shares common factors. How about we use prime $m$?
> [!info] Definition
>
>**Bertrand's Postulate**: For all $n$ there exists a prime $p$ satisfying $n < p < 2n - 2$.
Let $m$ be prime. We will use a mix of addition and multiplication with random coefficients, modulo $m$.
> [!example] Example
>
>$m=7$ and $|cal(U)| = 343 = 7^3$. All keys in $cal(U)$ can be written in base 7. In general, write $k = (k^((2)), k^((1)), k^((0)))$.
>
>Sample $a ~ "Unif"{0,...,6}^3$. Set $h_a (k) := (a^((2)) dot k^((2)) + a^((1)) dot k^((1)) + a^((0)) dot k^((0))) mod 7$.
In general, let $m$ be prime and $|cal(U)| = m^r$. Write each key in base $m$: $k = (k^((r-1)), ..., k^((1)), k^((0)))$. Sample $a ~ "Unif"{0,...,m-1}^r$ and defineh_a (k) := (sum_(i=0)^(r-1) a^((i)) dot k^((i))) mod m
> [!tip] Theorem
>
> This family $cal(H) = {h_a : a in {0,...,m-1}^r}$ is universal.
**Proof.** Fix two distinct keys $k != k'$. Since $k != k'$, there exists some coordinate $i^*$ where $k^((i^*)) != k^((i^*)')$. We want to show $PP_a [h_a (k) = h_a (k')] <= 1/m$.
The collision condition $h_a (k) = h_a (k')$ meanssum_(i=0)^(r-1) a^((i)) (k^((i)) - k^((i)’)) equiv 0 mod m
Isolate the coordinate $i^*$:a^((i^)) (k^((i^)) - k^((i^)’)) equiv -sum_(i != i^) a^((i)) (k^((i)) - k^((i)’)) mod m
Since $m$ is prime and $k^((i^*)) - k^((i^*)') != 0 mod m$, the factor $(k^((i^*)) - k^((i^*)'))$ has a multiplicative inverse mod $m$. So for any fixed choice of all the other $a^((i))$ with $i != i^*$, there is exactly one value of $a^((i^*)) in {0,...,m-1}$ that satisfies the equation. Since $a^((i^*))$ is uniform over $m$ values:PP_a [h_a (k) = h_a (k’) | a^((i)), i != i^*] = 1/m
This holds for every choice of the other coordinates, so $PP_a [h_a (k) = h_a (k')] = 1/m <= 1/m$. $square$
> [!question] Why do we need $m$ prime?
>
> The inverse of $(k^((i^*)) - k^((i^*)'))$ only exists mod $m$ when $gcd(k^((i^*)) - k^((i^*)'), m) = 1$. If $m$ is prime, every nonzero element has an inverse. If $m$ is composite, some nonzero differences would lack inverses, and the equation could have more (or fewer) than one solution for $a^((i^*))$, breaking the $1/m$ bound.